이전에 만든 repository는 JpaRepositroy를 상속받았기에 기본적인 crud 쿼리 메서드들을 사용할 수 있다. 추가로 디테일한 쿼리를 원하면, 우리가 직접 쿼리 메서드를 작성해서 커스텀이 가능하다. 그렇기에 JPQL(Java Persistence Query Language)의 사용이 필연적이게 된다. 문제는 원하는 쿼리가 복잡해질수록 너무 쿼리문자열, 또는 메서드 이름의 길이가길어져 가독성이 떨어지고, 오류도 체크하기 어려워진다. 그렇기에 우리는 querydsl을 사용하기로 결정했다.
querydsl 개요
querydsl은 SQL쿼리를 정적 타입을 이용해 생성하게 해주는 프레임워크이다. 이것을 이용하면 다음과 같은 장점이 있다.
1. 자동완성 기능을 사용할 수 있다.
2. 문법이 틀리면 오류를 바로 확인할 수 있다.
3. 동적 쿼리 생성이 가능하다.
4. 가독성이 좋다.
이러한 장점들이 우리가 이 방법을 선택한 이유가 되겠다.
querydsl 설정
querydsl은 분명 좋은 프레임워크이지만, 설정이 번거롭다는 단점이 있다. 물론 한 번 제대로 설정하면 그 뒤에 걱정할 것은 없기에 크게 와닿지는 않는다.
plugins {
id 'java'
id 'org.springframework.boot' version '3.0.6'
id 'io.spring.dependency-management' version '1.1.0'
}
group = 'com.9inProject'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '17'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
//spring boot
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'junit:junit:4.13.1'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
//lombok
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
//database
runtimeOnly 'org.mariadb.jdbc:mariadb-java-client'
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
//queryDsl
implementation 'com.querydsl:querydsl-jpa:5.0.0:jakarta'
implementation 'com.querydsl:querydsl-core:5.0.0'
annotationProcessor "com.querydsl:querydsl-apt:${dependencyManagement.importedProperties['querydsl.version']}:jakarta"
//java.lang.NoClassDefFoundError:javax/persistence/Entity 에러 방지를 위해 추가
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"
//check validation
implementation "org.springframework.boot:spring-boot-starter-validation"
}
tasks.named('test') {
useJUnitPlatform()
}
def querydslDir = "$buildDir/generated/querydsl"
sourceSets {
main.java.srcDirs += [ querydslDir ]
}
tasks.withType(JavaCompile) {
options.annotationProcessorGeneratedSourcesDirectory = file(querydslDir)
}
clean.doLast {
file(querydslDir).deleteDir()
}
build.gradle에 querydsl 의존성들을 추가한다. Q클래스들은 어디에 생성할 지 지정하는 것도 필요하다.

그 다음 config패키지에 QuerydslConfig 파일을 생성한다. 이는 JPAQueryFactory객체를 스프링 빈으로 등록해서 로직에서 사용할 때 마다 객체 생성할 필요없이 의존성 주입으로 가져올 수 있도록 하기 위함이다.
PersistenceContext는 entityManager를 등록하기 위한 어노테이션이다.
querydsl 사용
querydsl을 로직에 사용해본다. 먼저, querydsl을 효율적으로 사용하기 위해 우리는 인터페이스 상속 구조를 추가 및 변경했다.
Custom 리포지토리 인터페이스를 생성하고, 그 인터페이스의 구현체에 쿼리를 작성해 사용하는 방식을 사용했다. 그림으로 표현하면 다음과 같다.

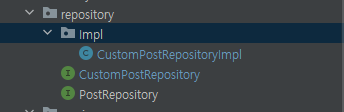
여기서 CustomUserRepositoryImpl만 클래스, 나머지는 인터페이스이다.
기본적으로 제공되는 JpaRepository 인터페이스의 쿼리들 말고 좀 더 디테일한 쿼리문을 코드로 CustomRepositoryImpl에 작성했다.
우리가 흔히 마주하는 게시판 글들을 페이지로 나눠서 띄우는 작업을 위한 쿼리를 작성해봤다.
public class CustomPostRepositoryImpl implements CustomPostRepository {
private final JPAQueryFactory jpaQueryFactory;
QPost qPost = QPost.post;
@Autowired
public CustomPostRepositoryImpl(JPAQueryFactory jpaQueryFactory){
this.jpaQueryFactory =jpaQueryFactory;
}
//Paging 사용. service에서 사용할 때 PageRequest 사용해야 함.
private JPAQuery<Long> getCount(){
JPAQuery<Long> count = jpaQueryFactory
.select(qPost.count())
.from(qPost);
return count;
}
@Override
public Page<Post> findAllPost(Pageable pageable) {
List<Post> content = jpaQueryFactory
.selectFrom(qPost)
.orderBy(qPost.createAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
JPAQuery<Long> count = getCount();
return PageableExecutionUtils.getPage(content, pageable, () -> count.fetchOne()); //count쿼리가 필요없을 때 사용하지 않는 최적화 적용.
//return new PageImpl(content, pageable, count);
}
}
findAllPost가 바로 모든 게시글을 쿼리하기 위한 메서드가 되겠다. Q클래스를 이용해 쿼리를 하며, 글이 작성된 시간 기준으로 최신순으로 정렬했다. paging을 사용했으며, 관련 게시글은 다음 링크에 작성했다.
2023.05.25 - [Backend/spring boot] - spring boot JPA : 페이징(paging)
spring boot JPA : 페이징(paging)
보통 게시판 화면을 보면 게시글이 특정 개수 단위로만 띄워진다. 모든 게시글을 한눈에 보이도록 제공하지는 않는다. 그렇게 하면 서버 부하도 심할 것이고, 보는 사용자 입장에서도 가시성이
yoonsys.tistory.com
중요한 것은 예전 글들을 보면 fetchResult같은 것을 사용해 count쿼리를 한 번에 처리하는 예시들이 이제는 참고할 수 없다는 것이다. 5.0.0 부터 count쿼리를 사실상 따로 처리하라고 밀고 있는 것 같다. 더 이상 fetchresult는 deprecated되어 사용하지 못한다. 그래서 count쿼리는 함수를 따로 만들어 사용한 모습을 볼 수 있다.
이제 test를 해보자. 데이터를 10개 정도 만들어 DB에 넣고 테스트하는 테스트코드를 작성했다.

코드를 동작해보면 다음과 같다.

limit, orderby가 잘 적용된 첫 번째 쿼리가 동작하고, 그 다음 count쿼리를 통해 데이터 총 개수를 센다. page 사이즈는 2로 했기에 한 페이지 2개의 post가 나오고, 가장 늦게 들어간 9번 부터 출력되는 모습을 볼 수 있다.
'Project > 9uin' 카테고리의 다른 글
| spring boot 사이드 프로젝트[8] : 게시글 태그 필터링 (querydsl join) (0) | 2023.06.14 |
|---|---|
| spring boot 사이드 프로젝트[7] : 게시글 검색 기능 구현, 동적 쿼리 적용 (0) | 2023.06.13 |
| spring boot 사이드 프로젝트[5] : service, repository 초기 작성 (0) | 2023.05.23 |
| spring boot 사이드 프로젝트[4] : 도메인 엔티티, DTO 설계 및 특별한 패키지 구조 (0) | 2023.05.22 |
| spring boot 사이드 프로젝트[3] : 개발 환경 설정 (0) | 2023.05.22 |